
0x0 MLSystemsRG: On the Use of LLMs in Data Lakes
Evaporate-Code+ (Arora et al.), From Words to Code (Khatry et al.)
Today, we are covering a research paper that describes a system which builds a queryable table from text, and another paper that describes a system which generates code for data manipulation tasks (ex. ‘trim the end of all contents in column "Path" by one character‘). Although we look at these problems in context of data lakes, they can be easily encountered in other workloads, such as web scraping.
Data lakes frequently store a large amount of unstructured/semi-structured data such as user-generated reviews, news articles, logs, contract documents, etc. Extracting value from text data is difficult because it usually requires a human with both domain and technical knowledge. Language models like GPT could automate the processing flow of unstructured/semi-structured data. Moreover, they could simplify data manipulation for users who are not programmers.
#1. Evaporate-Code+ (Arora et al.)
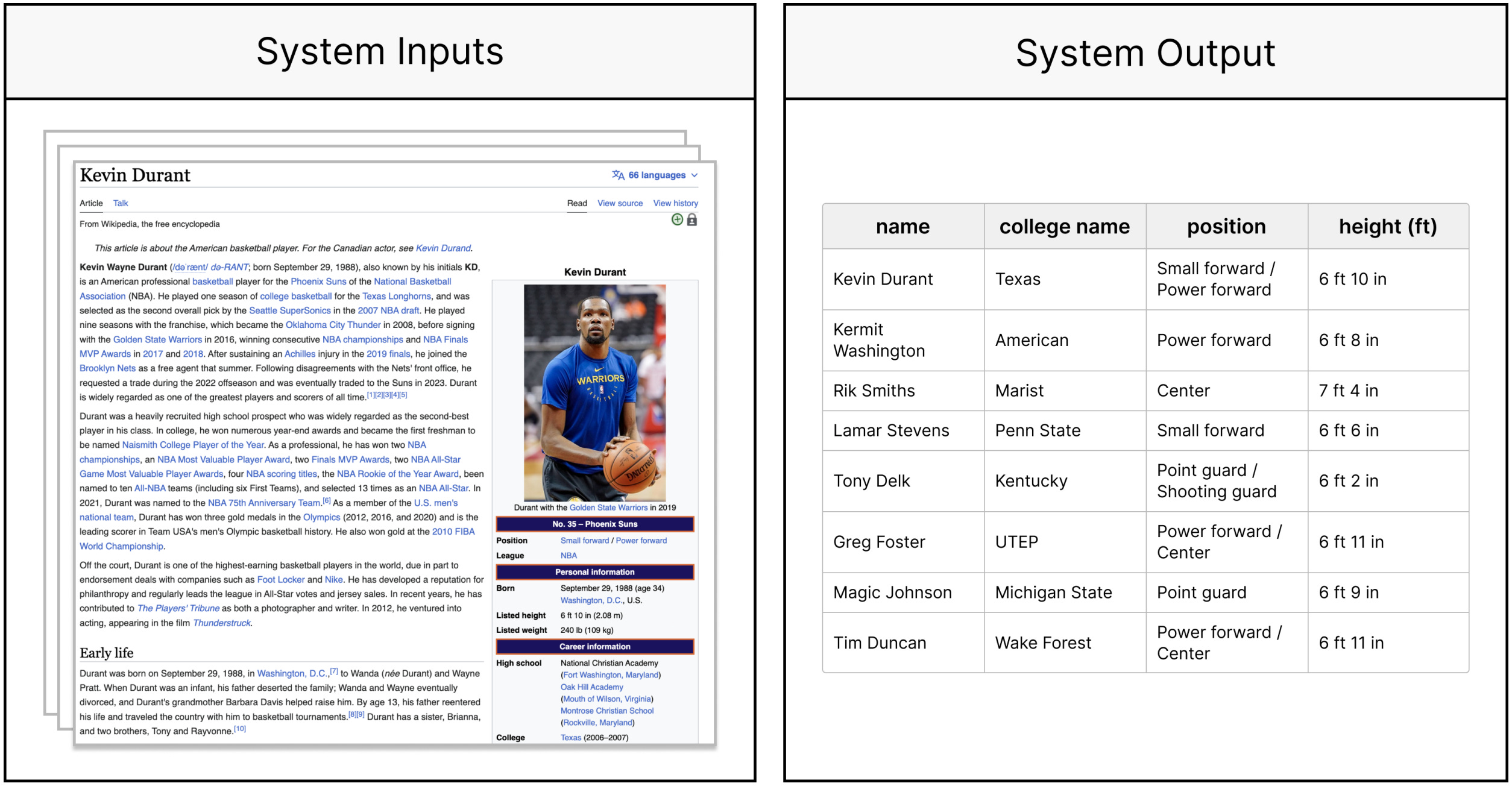
Evaporate-Code+ is a system developed by researchers at Stanford and Cornell that takes as input a set of semi-structured documents, automatically identifies important attributes/schema of the table, extracts values, and outputs a queryable table. In the image below, you can see an example where system was fed with Wikipedia articles about NBA players. It then automatically identified what should be the attributes of the table - name, college name, position, height (ft) - and finally, it populated the table with the extracted values.
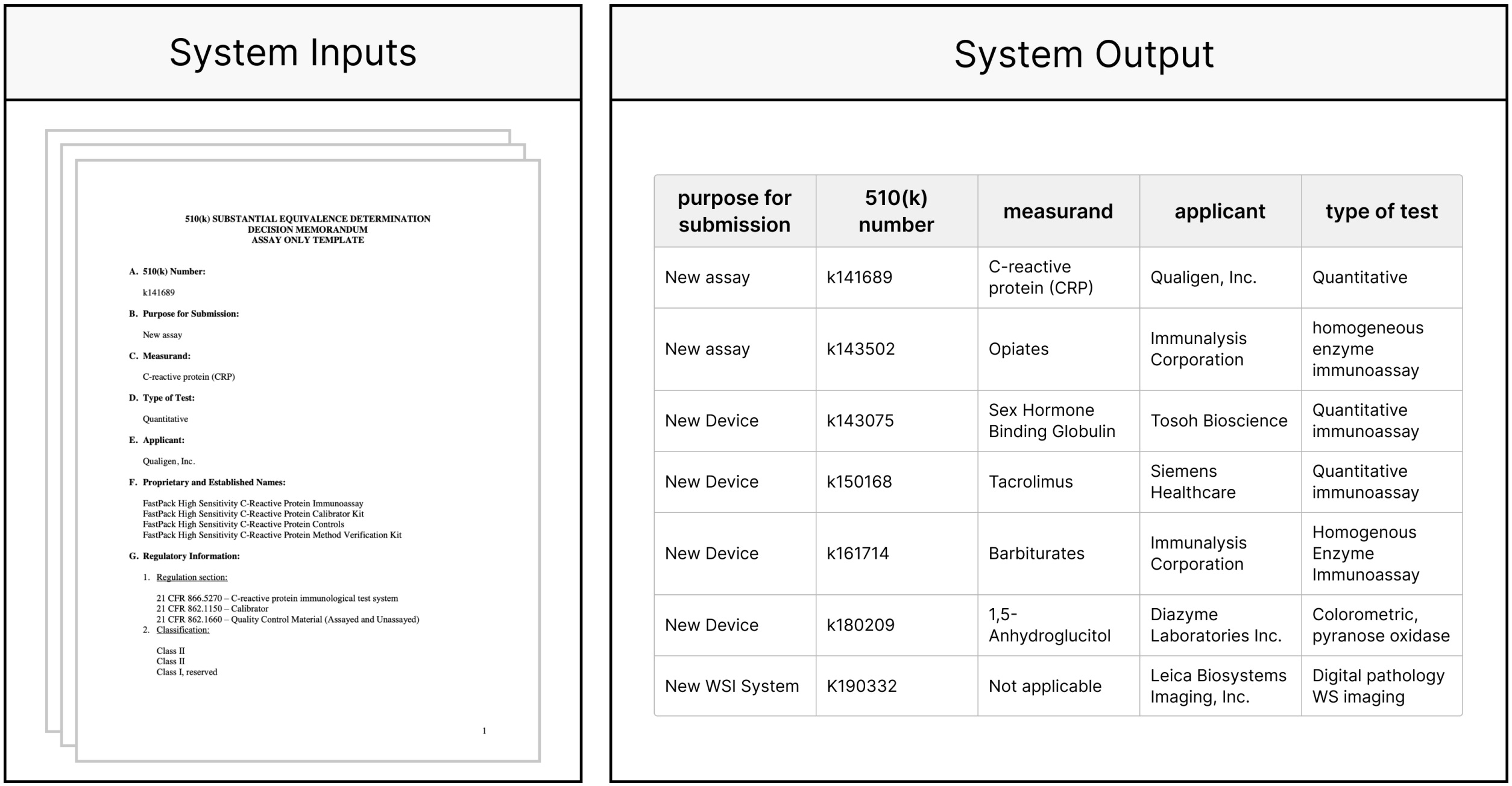
Another example involves a collection of FDA 510(k) documents, which contain governmental reviews of the safety and effectiveness of various medical devices.
So how does Evaporate-Code+ convert text to tables? The key idea motivating the design of the system is that prompting LLM to directly process documents is expensive but produces great results, while prompting LLM to generate Pythonic code, which can then be used to process documents, is cheap but far from accurate. Here is a rough outline of the algorithm:
Identify schema/attributes.
Select a small sample of documents.
Generate candidate attributes by iterating through each selected document and prompting the LLM to extract the most useful attributes from the document.
Give the union of extracted attributes to the LLM and instruct it to identify the most useful attributes.
Extract values to populate the table.
Prompt the LLM to synthesize many candidate Pythonic functions, which can then be applied across the documents to extract values.
Since some candidate Pythonic functions work better than others on different documents, use a weak supervision algorithm. This algorithm runs each function on a document and then aggregates the functions’ outputs to produce correct extracted values. The idea behind weak supervision is to get accurate results given multiple noisy sources. (P.S. The authors actually use the LLM again at this step as well, but they apply it only on a small set of documents to use as ground truth labels.)
Here is a diagram showing the entire flow:

Interestingly, the simple solution, which directly extracts values using LLM (without generating Pythonic functions), outperforms SOTA baseline systems. Using an LLM provides great benefits in terms of the quality of results and generality, since there is no need for task-specific training (authors did not fine-tune LLMs and used standard models like OpenAI GPT-4). However, the cost of directly using LLM is not viable, so Evaporate-Code+ is a solution which finds a balance among all three properties - cost, quality, and generality.
#2. From Words to Code (Khatry et al.)
In the paper ‘From Words to Code: Harnessing Data for Program Synthesis from Natural Language’ researchers at Microsoft propose a framework that takes a natural language (NL) description of data manipulation task and outputs code that performs the task. They claim the primary motivation for such a framework is to simplify work for people who might not be well familiar with data science and business intelligence tools like Pandas, SQL, or the data manipulation language M used in Excel.
So, what’s the problem? Why can’t we just provide a single prompt for LLM to generate code completing task such as ‘Trim the end of all contents in column "Path" by one character’? The problem is that after creating the best possible prompt and asking LLM to generate 25 candidate programs, the correct solution was buried in the list of incorrect candidates at position 10. “The default order produced by LLMs performs poorly”. “The best possible prompt“ here refers to a prompt that includes the NL query/task, the schema of the table, some sample rows from the table, and some examples of NL queries with corresponding code solutions (few-shot prompting).
Here is the rough outline of the framework that produces candidates in the order where the first candidate is likely to be the correct one:
Give the LLM “the best possible prompt“ to generate candidate programs using temperature mixing. Temperature mixing is a novel technique proposed by authors that helps avoid scenario where a correct program is not included in the candidate set produced by the LLM. This technique involves tweaking the sampling temperature, a hyperparameter of the LLM that controls the randomness of generated output. The higher the temperature, the more likely it is that the next time you run LLM with the same prompt, the output will be different. The authors claim that in the context of code generation, they noticed a tradeoff: the higher the temperature, the more diverse generated candidates, but the top-1 accuracy drops.
For each generated candidate, calculate the average logprob score. Logprob is a value provided by LLM and it contains the log of the probability that a token comes next. A higher logprob of a token in a language model means that the model thinks it is more likely that this token is the next one in the sequence. This is based on what the model has learned during its training about the patterns of how words and phrases tend to come together in the language. To calculate the score of a candidate program, take the average of its tokens’ logprob scores.
Rerank the generated candidates in a list using a technique termed semantic reranking. Run each candidate on the input dataset or subset of it to get the corresponding outputs. Perform semantic filtering, which involves removing candidates whose execution failed. Perform semantic interleaving, which involves moving candidates that generate the same output as some higher-ranked candidate lower in the ordering, in order to increase the diversity of the top-K candidates.

The architecture of the framework is shown in the diagram above. In this case, the list of candidate programs produced by the LLM is shown at step 2. The correct solution E is initially at fifth position in the list, but after processing the list with the framework, the correct solution ends up being the first one. While we have covered the framework at a high level, it is important to note authors’ comment - “A crucial distinction with all previous work is that our contributions are not just empirical and we provide theoretical justification for interleaving.”
Concluding Remarks
Each paper has multiple novel contributions, but if we were to summarize the main ideas which are present in both papers, here’s what they would be:
LLMs are great but expensive for processing data directly.
LLMs are not great for generating code for data manipulations, but running generated code is cheaper than running LLM.
A possible solution is to prompt the LLM to generate multiple candidate programs and then perform post-processing of candidates to identify the correct solution.
Post-processing of candidates should involve the data context, meaning the outputs of candidate programs on a sample dataset can help find the correct solution.